Search API v1
Huwise datasets are accessible by developers through an HTTP REST API.
The domain https://documentation-resources.huwise.com is used to illustrate examples in the following documentation.
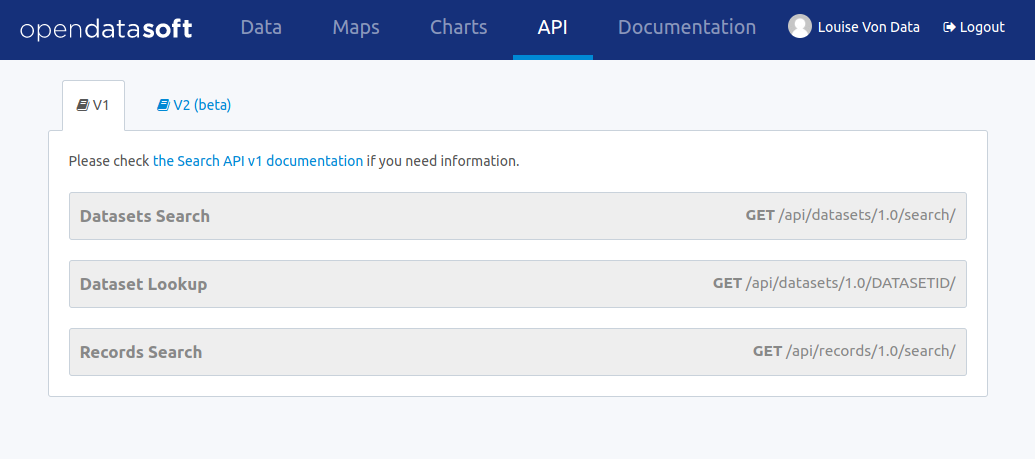
Available APIs
The available APIs are listed below.
| API Name | Description |
|---|---|
| Dataset search API | Search datasets in a catalog |
| Dataset lookup API | Find a dataset based on its identifier |
| Records search API | Search records within a given dataset |
| Records lookup API | Find a record based on its identifier |
| Analysis API | Build advanced aggregations of records from a given dataset |
| Download API | Efficiently download a large number of records from a given dataset |
| Geo clustering API | Build geo clusters of records from a given dataset |
| Real time push API | Push new records to a given dataset in real time |
| Multimedia download API | Download multimedia content attached to a dataset or a record |
These APIs return JSON by default, except:
- the download API that returns CSV by default but supports several output formats like JSON and geographic formats
- the multimedia download API that depends on the file
The real time push API is very specific and will not be detailed in the following documentation. Please refer to the platform documentation for more information about this API.
These APIs support cross-domain access from a browser using CORS. For older browsers or other specific purposes, JSONP is supported when returning JSON content by adding a callback parameter.
Finding a dataset identifier
To access a dataset directly via the dataset lookup API or record related APIs, its identifier must be provided. This identifier is found in the information tab of each dataset.
HTTP Methods
All API endpoints support both GET and POST requests. GET methods are preferred, but POST methods can be used to work around browser, library or proxy limitations regarding the size of HTTP URLs.
Security
All API endpoints are protected by the same authentication and authorization model.
Anonymous access and authenticated users can be restricted to:
- a subset of the domain's datasets
- a subset of records in a given dataset
All API endpoints are available in HTTPS, which use is highly recommended wherever possible.
The following authentication modes are available:
- API key authentication: via an API key generated from the account settings page
- Session authentication: API calls performed from a browser will authenticate logged users via the Huwise session cookie
Quotas
All API endpoints are subject to quota-based limitations. According to the domain configuration, authenticated users may have extended quotas compared to anonymous access. Please contact the domain administrator for more information about a user's quotas.
The API response contains three headers to indicate the current state of a user's quota:
- X-RateLimit-Limit indicates the total number of API calls the user can do in a single day (resets at midnight UTC)
- X-RateLimit-Remaining indicates the remaining number of API calls for the user until reset
- X-RateLimit-Reset indicates the epoch of the next reset time
Errors handling
Example of an error occurring when you reach the domain requests limit
> GET https://documentation-resources.huwise.com/api/datasets/1.0/search/ HTTP/1.1
< HTTP/1.0 429 TOO MANY REQUESTS
{
"errorcode": 10002,
"reset_time": "2021-01-26T00:00:00Z",
"limit_time_unit": "day",
"call_limit": 10000,
"error": "Too many requests on the domain. Please contact the domain administrator."
}
Example of an error occurring when you reach the requests limit for anonymous users
> GET https://documentation-resources.huwise.com/api/datasets/1.0/search/ HTTP/1.1
< HTTP/1.0 429 TOO MANY REQUESTS
{
"errorcode": 10005,
"reset_time": "2021-01-26T00:00:00Z",
"limit_time_unit": "day",
"call_limit": 1000,
"error": "You have exceeded the requests limit for anonymous users."
}
When an error occurs, a JSON object describing the error is returned by the API.
Authentication
An authenticated user can be granted access to restricted datasets and benefit from extended quotas for API calls. The API features an authentication mechanism for users to be granted their specific authorizations.
For the platform to authenticate a user, you need to either:
- be logged in a portal so a session cookie authenticating your user is passed along your API calls, or
- provide an API key via the Authorization header or as a query parameter.
Finding and generating API keys
API keys are managed via your user profile page at https://<domain_id>.com/account/ or by clicking on your name in the header.
Go to the tab named API keys to see your existing API keys, revoke them and create new ones.
Providing API keys within requests
Unauthenticated request on a private portal
> GET https://private-portal.huwise.com/api/v2/catalog/datasets/ HTTP/1.1
< HTTP/1.0 401 Unauthorized
Authenticated request using an
Authorization: Apikey <API_KEY>header
> GET https://private-portal.huwise.com/api/v2/catalog/datasets/ HTTP/1.1
Authorization: Apikey 7511e8cc6d6dbe65f9bc8dae19e08c08a2cab96ef45a86112d303eee
< HTTP/1.0 200 OK
{
"total_count": 4,
"links": [{
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "self"
}, {
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "first"
}, {
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "last"
}],
"datasets": [...]
}
Authenticated request using an API key as a query parameter
> GET https://private-portal.huwise.com/api/v2/catalog/datasets/?apikey=7511e8cc6d6dbe65f9bc8dae19e08c08a2cab96ef45a86112d303eee HTTP/1.1
< HTTP/1.0 200 OK
{
"total_count": 4,
"links": [{
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "self"
}, {
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "first"
}, {
"href": "https://private-portal.huwise.com/api/v2/catalog/datasets?include_app_metas=False&limit=10&offset=0",
"rel": "last"
}],
"datasets": [...]
}
If you try to access a private portal's catalog without being authenticated, the API returns a 401 Unauthorized error.
After generating an API key, you can use it to make authenticated requests. Depending on the permissions granted to the user for which the API key has been created, the JSON response contains only data about the datasets this user can access on the portal.
It is good practice to pass the API key to the Authorization header in the following format:
Authorization: Apikey <API_KEY>
Alternatively, you can pass the API key as a query parameter in the following format:
apikey=<API_KEY>
Replace <API_KEY>with your API key.
Using OAuth2 authorization
Overview
Huwise implements the OAuth2 authorization flow, allowing third party application makers to access the data hosted on an Huwise platform on behalf of a user while never having to deal with a password, thus avoiding any user credential to be compromised.
The Huwise OAuth2 authorization flow is compliant with RFC 6749 and makes use of Bearer Tokens in compliance with RFC 6750.
Application developers who want to use the Huwise APIs with OAuth2 must go through the following steps, which will be explained in this section.
- Register their application with the Huwise platform.
- Request approval from users via an OAuth2 authorization grant.
- Request a bearer token that will allows them to query the Huwise platform APIs for a limited amount of time.
- Refresh the Bearer Token when it expires.
Currently, applications are registered on a specific domain and can only access data on this domain.
Register an application for OAuth2 authentication
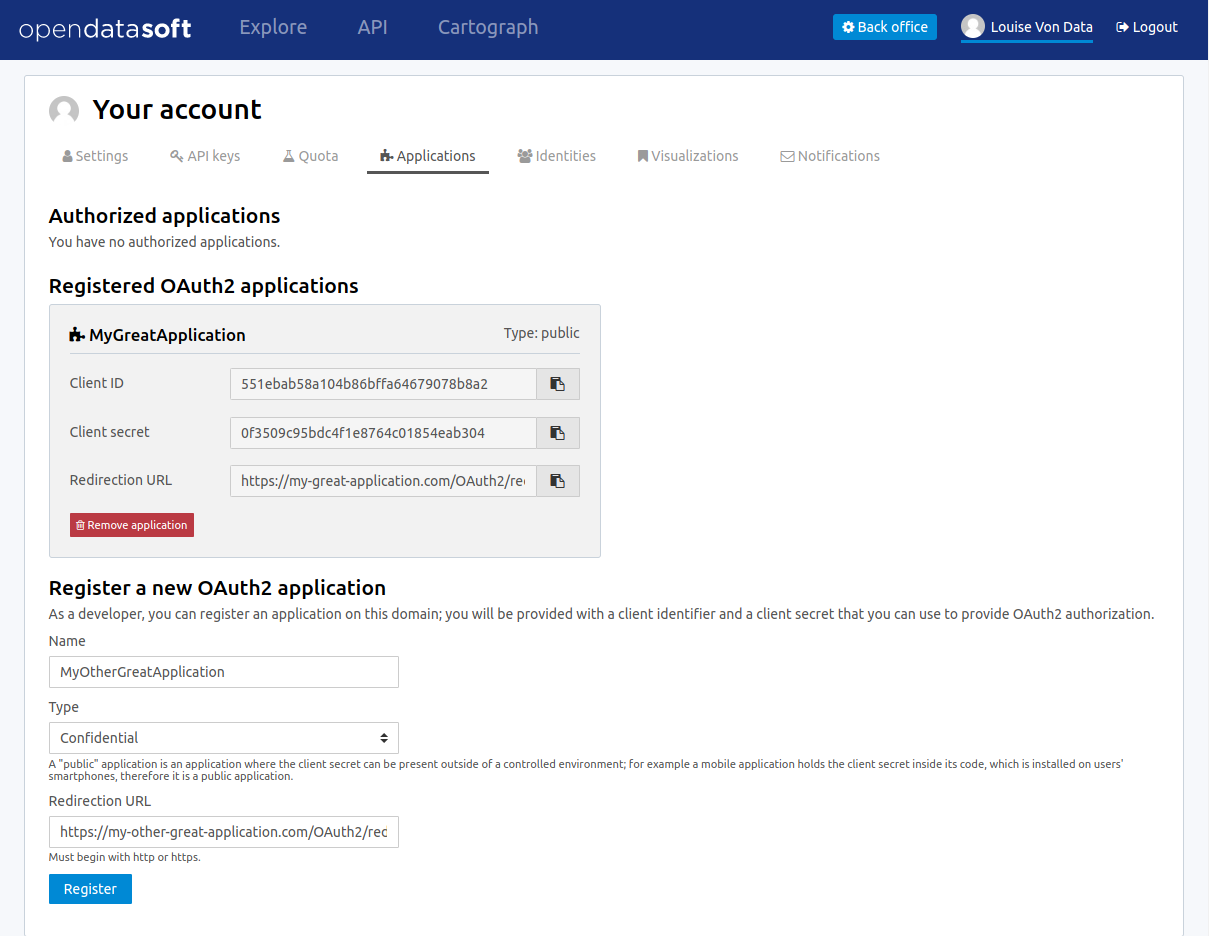
- Go to the My applications tab of your account page on the domain you want to register the application on.
- Fill the registration form with the following information:
- Application name: the name of the application
- Type:
- confidential: client password is kept secret from the user and only used from a trusted environment (e.g: a web service, where the client password is stored server-side and never sent to the user)
- public: client password is embedded in a client-side application, making it potentially available to the world (e.g: a mobile or desktop application)
- Redirection URL: the URL users will be redirected to after they have granted you permission to access their data
- Store the resulting client ID and client secret that will be needed to perform the next steps.
Getting an authorization grant
Example call to
/oauth2/authorize/
GET /oauth2/authorize/?
client_id=123456789&
redirect_uri=https://example.com&
response_type=code&
state=ilovedata&
scope=all HTTP/1.1
To get an authorization grant from a user:
- Redirect them to
/oauth2/authorize/with the appropriate query parameters. - The user will then be authenticated in the platform and redirected to a page identifying your application.
- From there, the user will review the information you filled in the form described above and the scope of the requested access, and grant your application the right to access their data.
- Once the user has accepted those terms, they will be redirected to your application's redirection URL with query parameters describing your authorization grant.
The query parameters you need to supply when redirecting the user are the following:
client_id: the client ID you were given during registrationredirect_uri: the redirect URI you provided during registrationresponse_type: this should always be set tocodescopes(optional): a list of space-separated requested scopes. Currently onlyallis supportedstate(optional): a random string of your choice
Redirection following a successful authorization
HTTP/1.0 302 FOUND
Location: https://example.com?state=ilovedata&code=gKnAQc2yIfdz2mY25xxgpTY2uyG5Sv
The authorization grant redirect will have these values:
code: a 30-characters-long authorization codestate: the state passed in the request described above
The 30-character authorization code must now be converted into a bearer token within 1 hour before expiring.
Converting an authorization grant to a bearer token
Example call to
/oauth2/token/
POST /oauth2/token/ HTTP/1.1
client_id=cid&
client_secret=csc&
grant_type=authorization_code&
code=GokshWxRFXmW0MaLHkDv5HrG6wieGs&
scopes=all&
redirect_uri=https://example.com&
state=ilovedata
To receive a bearer token, convert the previously obtained authorization grant via a POST request to /oauth2/token/ with the following parameters:
client_id: the client ID you were given during registrationclient_secret: the client secret you were given during registrationredirect_uri: the redirect URI you provided during registrationgrant_type: this should always be set toauthorization_codecode: the 30-character authorization code received as an authorization grantscopes(optional): a list of space-separated requested scopes. Currently onlyallis supportedstate(optional): a random string of your choice
Alternative call with an
Authorizationheader
POST /oauth2/token/ HTTP/1.1
Authorization: Basic Y2lkOmNzYw==
grant_type=authorization_code&
code=GokshWxRFXmW0MaLHkDv5HrG6wieGs&
scopes=all&
redirect_uri=https://example.com&state=ilovedata
Alternatively, you can pass your client ID and client secret through the Authorization header
Example response for a bearer token request
HTTP/1.0 200 OK
Content-Type: application/json
{
"access_token": "9kxoTUYvSxnAiMpv008NBqRiqk5xWt",
"expires_in": 3600,
"token_type": "Bearer",
"state": "ilovedata",
"scope": "all",
"refresh_token": "jFfDUcsK9zzNMs1zwczzJxGrimPtmf"
}
The response to this request is a JSON representation of a bearer token, which contains the following values:
access_token: the token you can use to access the user's data.expires_in: the number of seconds before token expirationtoken_type: the type of the token. It will always beBearerstate: the state passed in the request described abovescope: the list of scopes of this authorization coderefresh_token: a refresh token that can be used to renew this bearer token when expired
Using the bearer token
Using the token as a query parameter
GET /api/end/point?access_token=9kxoTUYvSxnAiMpv008NBqRiqk5xWt HTTP/1.1
Using the token in an Authorization header
GET /api/end/point HTTP/1.1
Authorization: Bearer 9kxoTUYvSxnAiMpv008NBqRiqk5xWt
Using the token in the request body
GET /api/end/point HTTP/1.1
access_token=9kxoTUYvSxnAiMpv008NBqRiqk5xWt
The bearer token can be passed along requests for authentication in three different ways:
- as a query parameter of the request
- in the request's
Authorizationheader - in the request body
Refreshing a bearer token
Example token refresh call
POST /oauth2/token/ HTTP/1.1
client_id=cid&
client_secret=csc&
grant_type=refresh_token&
refresh_token=jFfDUcsK9zzNMs1zwczzJxGrimPtmf&
scopes=all&
redirect_uri=https://example.com&
state=ilovedata
To refresh an expired bearer token, send a request to the /oauth2/token/ endpoint, with the following query parameters:
client_id: the client ID you were given during registrationclient_secret: the client secret you were given during registrationrefresh_token: the refresh token returned in the bearer token responsegrant_type: this should always be set torefresh_tokenscopes: a list of space-separated requested scopes. Currently onlyallis supportedstate(optional): a random string of your choice
The response to this request is identical to the bearer token response.
Query Language and Geo Filtering
Filtering features are built in the core of the Huwise API engine. Many of the previously listed APIs can take filters as parameters, so that the response only contains the datasets or records you want.
Note that a given filtering context can simply be copied from one API to another. For example, you can easily build a user interface that first allows the user to visually select the records they are interested in, using full-text search, facets, and geo filtering, and then allowing them to download these records with the same filtering context.
Query language
The Huwise query language makes it possible to express complex boolean conditions as a filtering context.
The user query can most of the time be expressed through the q HTTP parameter.
Full-text search
q=film -> results that contain film, films, filmography, etc.
q="film" -> results containing exactly film.
The query language accepts full-text queries.
If a given word, or compounds, is surrounded with double quotes, only exact matches are returned (modulo an accent and case insensitive match).
Boolean expressions
film OR trees
(film OR trees) AND paris
The query language supports the following boolean operators AND, OR, and NOT.
Parenthesis can be used to group together expressions and alter the default priority model:
NOTANDOR
Field queries
Search on the
documentation-resourcesdomain for datasets having "Paris" in their title or description and containing at least 50 records
GET https://documentation-resources.huwise.com/api/datasets/1.0/search?q=(title:paris OR description:paris) AND records_count >= 50
One of the major features of the query language is to allow per field filtering. You can use field names as a prefix to your queries to filter the results based on a specific field's value.
For the dataset search API, the list of available fields corresponds exactly to available metadata. By default
| Field name | Description |
|---|---|
publisher |
The dataset publisher |
title |
The dataset title |
description |
The dataset description |
license |
The dataset license |
records_count |
The number of records in the dataset |
modified |
The last modification date of the dataset |
language |
The language of the dataset (iso code) |
theme |
The theme of the dataset |
references |
The references for the dataset |
The domain administrator might define a richer metadata template, thus giving access to a richer set of filtering fields.
Examples of queries for the record search API
film_date >= 2002
film_date >= 2013/02/11
film_date: [1950 TO 2000]
film_box_office > 10000 AND film_date < 1965
For the record search API, the list of available fields depends on the schema of the dataset. To fetch the list of available fields for a given dataset, you may use the search dataset or lookup dataset APIs.
Multiple operator fields can be used between the field name and the query:
:,-,==: return results whose field exactly matches the given value (granted the fields are of text or numeric type)>,<,>=,<=: return results whose field values are larger, smaller, larger or equal, smaller or equal to the given value (granted the field is of date or numeric type)[start_date TO end_date]: query records whose date is betweenstart_dateandend_date
Date formats can be specified in different formats: simple (YYYY[[/mm]/dd]) or ISO 8601 (YYYY-mm-DDTHH:MM:SS)
Query language functions
Return records in
birthdatefield that are smaller or equal to the current datetime:
birthdate <= #now()
Return empty records in
birthdatefield:
#null(birthdate)
Return records in
firstnamefield that contain "Marie":
#exact(firstname, "Marie")
Return records where
fistnamefield contains "Jean" followed by a word starting with "c":
#search(firstname, "Jean-C")
Return records in
firstnamefield that start with "Mar":
#startswith(firstname, "Mar")
Return records in
locationfield which point is maximum 1 meter away from "48.864923, 2.382842":
#distance(location, "48.864923, 2.382842", 1)
Return records in
locationfield that are within the given polygon:
#polygon(location, “(48.36208891167685,-5.053710937499999),(51.03310377200486,2.0654296875),(48.88494684672119,8.3056640625),(44.04653631510921,7.55859375),(42.21875444410035,2.8125),(43.18755555543226,-1.9775390625),(48.36208891167685,-5.053710937499999)“)
Return records in
coordinatesfield which value is a polygon:
#geometry(coordinates, “polygon”)
Advanced functions can be used in the query language. Function names need to be prefixed with a sharp (#) sign.
| Function name | Description |
|---|---|
now |
Return the current date. This function should be called as a query value for a field |
null |
Search for records where no value is defined for the given field |
exact |
Search for records with a field exactly matching a given value |
search |
Search for records with one or more fields with a word starting with a given value |
startswith |
Search for records with a field starting with a given value (case sensitive). |
distance |
Search for records within a given distance from a given point |
polygon |
Search for records within a given polygon |
geometry |
Search for records which value (point, polygon) is a given type |
Available parameters for the #now function
#now(years=-1, hours=-1) -> current date minus a year and an hour
- years, months, weeks, days, hours, minutes, seconds, microseconds: these parameters add time to the current date.
#now(year=2001) -> current time, day and month for year 2001
- year, month, day, hour, minute, second, microsecond: can also be used to specify an absolute date.
#now(weeks=-2, weekday=1) -> Tuesday before last
#now(weekday=MO(2)) -> Monday after next
- weekday: Specifies a day of the week. This parameter accepts either an integer between 0 and 6 (where 0 is Monday and 6 is Sunday) or the first two letters of the day (in English) followed by the cardinal of the first week on which to start the query.
Usage of the #search function
#search function accepts multiple fields.
The n first parameters are the fields to search in, and the last parameter is the string value to search for.
#search(firstname, lastname, "Jean") -> search for firstname or lastname containing "Jean"
The function also accepts * character as first parameter to search in all fields.
#search(*, "Jean") -> search for records containing "Jean" in their fields
When search value contains multiple words, only the last word is treated as a prefix.
#search(firstname, "Jean-C") -> search for firstname containing Jean followed by a word starting with "c"
When searching for a small prefix, #search function can sometimes return incomplete results.
For complete results consider using #startswith function or contact the support.
Geo Filtering
Examples of geo filtering expressions
geofilter.distance=48.8520930694,2.34738897685,1000
geofilter.polygon=(48.883086, 2.379072), (48.879022, 2.379930), (48.883651, 2.386968)
Records search APIs accept geofilter parameters to filter in records which are located in a specific geographical area.
The following parameters may be used.
| Parameter Name | Description |
|---|---|
geofilter.distance |
Limit the result set to a geographical area defined by a circle center (WGS84) and radius (in meters): latitude, longitude, distance |
geofilter.polygon |
Limit the result set to a geographical area defined by a polygon (points expressed in WGS84): ((lat1, lon1), (lat2, lon2), (lat3, lon3)) |
Using facets
A facet can be considered as a valued tag associated with a record. For instance, let's say a dataset has a facet "City". A record in this dataset could have the value "Paris" for the "City" facet.
Facets are, for instance, used for building the left navigation column, both for dataset catalog exploration page and dataset records exploration page.
Facets are especially useful to implement guided navigation in large result sets.
Identifying facets
By default, in dataset and record APIs, faceting is disabled. Faceting can be enabled by using the "facet" API parameter, specifying the name of the facet to retrieve.
In the dataset APIs, facets are the same for all datasets and are the following:
| Facet Name | Description |
|---|---|
modified |
Last modification date |
publisher |
Producer |
issued |
First publication date |
accrualperiodicity |
Publication frequency |
language |
Language |
license |
Licence |
granularity |
Data granularity |
dataquality |
Data quality |
theme |
Theme |
keyword |
Keywords |
created |
Creation date |
creator |
Creator |
contributor |
Contributors |
API response showing fields available as facets
{
/* ... */
"fields": [
/* ... */
{
"label": "City",
"type": "text",
"name": "city",
"annotations": [
{
"name": "facet"
}
]
},
/* ... */
],
/* ... */
}
In the records API, facets are defined at the field level. A field facet can be available depending on the data producer choices. Fields (retrieved, for instance, from the Dataset Lookup API) for which faceting is available can be easily identified as shown in the example on the right.
When faceting is enabled, facets are returned in the response after the result set.
Every facet has a display value ("name" attribute) and a refine property ("path" attribute) which can be used to alter the query context.
Example of a facet tree
"facet_groups": [
{
"name": "modified",
"facets": [
{
"name": "2012",
"path": "2012",
"facets": [
{
"name": "09",
"path": "2012/09",
"facets": [
{
"name": "11",
"path": "2012/09/11"
}
/* ... */
]
},
/* ... */
]
},
/* ... */
]
},
/* ... */
]
Facets are hierarchical. For instance, a year facet will contain months facets, and a month facet will contain days facets.
Example of a facet with all its attributes
{
"facet_groups": [
{
"name": "modified",
"count": 822,
"facets": [
{
"name": "2013",
"path": "2013",
"count": 154,
"state": "displayed"
},
{
"name": "2014",
"path": "2014",
"count": 120,
"state": "displayed"
}
]
}
]
}
Every facet contains two additional information:
- the
countattribute contains the number of hits that have the same facet value the
stateattribute defines whether the facet is currently used in arefineor in anexclude. Possible values for the state attribute are:- displayed: no refine nor exclude
- refined: refine
- excluded: exclude
Refining
Refining on the facet "modified"
{
"facet_groups": [
{
"name": "modified",
"count": 462,
"facets": [
{
"name": "2013",
"path": "2013",
"count": 154,
"state": "refined",
"facets": [
{
"name": "08",
"path": "2013/08",
"count": 74,
"state": "displayed"
},
/* ... */
]
}
]
}
]
}
It is possible to limit the result set by refining on a given facet value. To do so, use the following API parameter:
refine.FACETNAME=FACETVALUE.
For example: https://documentation-resources.huwise.com/api/datasets/1.0/search?refine.modified=2020.
In the returned result set, only the datasets modified in 2020 will be returned.
As the refinement occurs on the "year" and as the "modified" facet is hierarchical, the sub-level is returned. Results are dispatched in the "month" sub value.
Excluding
Using the same principle as above, it is possible to exclude from the result set the hits matching a given value of a
given facet. To do so, use the following API parameter: exclude.FACETNAME=FACETVALUE.
For example: https://documentation-resources.huwise.com/api/datasets/1.0/search?exclude.modified=2020
Only results that have not been modified in 2020 will be returned.
Disjunctive faceting
By default, faceting is conjunctive. This means that the following context will lead down to no results: https://documentation-resources.huwise.com/api/datasets/1.0/search?refine.modified=2020&refine.modified=2021.
You can enable disjunctive faceting using the following API parameter: disjunctive.FACETNAME=true.
Dataset Catalog APIs
Dataset Search API
GET /api/datasets/1.0/search HTTP/1.1
Examples of Dataset Search Queries
https://documentation-resources.huwise.com/api/datasets/1.0/search?refine.language=en&refine.modified=2021/01
https://documentation-resources.huwise.com/api/datasets/1.0/search?exclude.publisher=GeoNames&sort=-modified
This API provides a search facility in the dataset catalog. Full-text search as well as multi-criteria field queries are made possible, and results facetting is provided as well.
Parameters
| Parameter | Description |
|---|---|
q |
Full-text query performed on the result set |
facet |
Activate faceting on the specified field (see list of fields in the Query Language section). This parameter can be used multiple times to activate several facets. By default, faceting is disabled |
refine.<FACET> |
Limit the result set to records where FACET has the specified value. It can be used several times for the same facet or for different facets |
exclude.<FACET> |
Exclude records where FACET has the specified value from the result set. It can be used several times for the same facet or for different facets |
sort |
Sorts results by the specified field. By default, the sort is descending. A minus sign - may be used to perform an ascending sort. Sorting is only available on numeric fields (Integer, Decimal), date fields (Date, DateTime), and on text fields that have the sortable annotation |
rows |
Number of results to return in a single call. By default, 10 results are returned. While you can request up to 10 000 results in a row, such requests are not optimal and can be throttled. So, you should consider splitting them into smaller ones. |
start |
Index of the first result to return (starting at 0). Use in conjunction with rows to implement paging |
pretty_print |
If set to true (default is false), pretty prints JSON and JSONP output |
format |
Format of the response output. Can be json (default), jsonp, csv or rss |
callback |
JSONP callback (only in JSONP requests) |
Dataset Lookup API
GET /api/datasets/1.0/<dataset_id> HTTP/1.1
Example of Dataset Lookup API URL
https://documentation-resources.huwise.com/api/datasets/1.0/doc-geonames-cities-5000/?pretty_print=true&format=json
Example of JSONP request
https://documentation-resources.huwise.com/api/datasets/1.0/doc-geonames-cities-5000/?format=jsonp&callback=myFunction
This API makes it possible to fetch an individual dataset information.
Parameters
The dataset identifier is passed as a part of the URL as indicated by the <dataset_id> placeholder in the example on the right.
Other parameters, passed as query parameters, are described below:
| Parameter | Description |
|---|---|
pretty_print |
If set to true (default is false), pretty prints output |
format |
Format of the response output. Can be json (default) or jsonp |
callback |
JSONP callback (only in JSONP requests) |
Dataset Records APIs
Record Search API
GET /api/records/1.0/search HTTP/1.1
This API makes it possible to perform complex queries on the records of a dataset, such as full-text search or geo filtering.
It also provides faceted search features on dataset records.
Parameters
| Parameter | Description |
|---|---|
dataset |
Identifier of the dataset. This parameter is mandatory |
q |
Full-text query performed on the result set |
geofilter.distance |
Limit the result set to a geographical area defined by a circle center (WGS84) and radius (in meters): latitude, longitude, distance |
geofilter.polygon |
Limit the result set to a geographical area defined by a polygon (points expressed in WGS84): ((lat1, lon1), (lat2, lon2), (lat3, lon3)) |
facet |
Activate faceting on the specified field. This parameter can be used multiple times to simultaneously activate several facets. By default, faceting is disabled. Example: facet=city |
refine.<FACET> |
Limit the result set to records where FACET has the specified value. It can be used several times for the same facet or for different facets |
exclude.<FACET> |
Exclude records where FACET has the specified value from the result set. It can be used several times for the same facet or for different facets |
fields |
Restricts field to retrieve. This parameter accepts multiple field names separated by commas. Example: fields=field1,field2,field3 |
pretty_print |
If set to true (default is false), pretty prints JSON and JSONP output |
format |
Format of the response output. Can be json (default), jsonp, geojson, geojsonp, rss, atom |
callback |
JSONP or GEOJSONP callback |
sort |
Sorts results by the specified field (for example, record_timestamp). By default, the sort is descending. A minus sign - may be used to perform an ascending sort. Sorting is only available on numeric fields (Integer, Decimal), date fields (Date, DateTime), and on text fields that have the sortable annotation |
rows |
Number of results to return in a single call. By default, 10 results are returned. While you can request up to 10 000 results in a row, such requests are not optimal and can be throttled. So, you should consider splitting them into smaller ones or use the Records Download API. Note also that the cumulated value of the parameters start and rows cannot go over 10 000. It means that with the Records Search API, there's no way to access a result with a position greater than 10 000. If you need to do so, consider again using the Records Download API. |
start |
Index of the first result to return (starting at 0). Use in conjunction with "rows" to implement paging |
Record Lookup API
GET /api/datasets/1.0/<dataset_id>/records/<record_id> HTTP/1.1
Example lookup for the record
d087227c3595eb1e5b7d09dacfdfd6cafb86562ain the datasetdoc-geonames-cities-5000:
https://documentation-resources.huwise.com/api/datasets/1.0/doc-geonames-cities-5000/records/d087227c3595eb1e5b7d09dacfdfd6cafb86562a
{
"datasetid": "doc-geonames-cities-5000",
"recordid": "d087227c3595eb1e5b7d09dacfdfd6cafb86562a",
"fields": {
"name": "Paris",
"modification_date": "2020-05-26",
"geonameid": "2988507",
"feature_class": "P",
"admin2_code": "75",
"geo_point_2d": [
48.85341,
2.3488
],
"timezone": "Europe/Paris",
"feature_code": "PPLC",
"dem": 42,
"country_code": "FR",
"admin1_code": "11",
"alternatenames": "Baariis,Bahliz,Ile-de-France,Lungsod ng Paris,Lutece,Lutetia,Lutetia Parisorum,Lutèce,PAR,Pa-ri,Paarys,Palika,Paname,Pantruche,Paraeis,Paras,Pari,Paries,Parigge,Pariggi,Parighji,Parigi,Pariis,Pariisi,Pariizu,Pariižu,Parij,Parijs,Paris,Parisi,Parixe,Pariz,Parize,Parizh,Parizh osh,Parizh',Parizo,Parizs,Pariž,Parys,Paryz,Paryzh,Paryzius,Paryż,Paryžius,Paräis,París,Paríž,Parîs,Parĩ,Parī,Parīze,Paříž,Páras,Párizs,Ville-Lumiere,Ville-Lumière,ba li,barys,pairisa,pali,pari,paris,parys,paryzh,perisa,pryz,pyaris,pyarisa,pyrs,Île-de-France,Παρίσι,Париж,Париж ош,Парижь,Париз,Парис,Парыж,Паріж,Փարիզ,פאריז,פריז,باريس,پارىژ,پاريس,پاریس,پیرس,ܦܐܪܝܣ,पॅरिस,पेरिस,पैरिस,প্যারিস,ਪੈਰਿਸ,પૅરિસ,பாரிஸ்,పారిస్,ಪ್ಯಾರಿಸ್,പാരിസ്,ปารีส,ཕ་རི།,ပါရီမြို့,პარიზი,ፓሪስ,ប៉ារីស,パリ,巴黎,파리",
"asciiname": "Paris",
"population": 2138551
},
"geometry": {
"type": "Point",
"coordinates": [
2.3488,
48.85341
]
},
"record_timestamp": "2021-01-04T11:22:14.440000+00:00"
}
This API makes it possible to fetch an individual record using its identifier (Record ID).
Parameters
| Parameter | Description |
|---|---|
datasetid |
Part of the URL path. Identifier of the dataset |
recordid |
Part of the URL path. Identifier of the record |
pretty_print |
If set to true (default is false), pretty prints JSON and JSONP output |
format |
Format of the response output. Can be json (default) or jsonp |
callback |
JSONP callback |
Record Analysis API
GET /api/records/1.0/analyze HTTP/1.1
This API provides powerful analytics features over a set of selected records.
It returns analyzed results in light and easy to parse format, which can be used as an input of modern charting libraries such as Highchart.js or D3.js.
Parameters
Filtering parameters
Count cities with a population greater than 5,000 inhabitants in each country code, filtered by a polygon in Central Europe:
https://documentation-resources.huwise.com/api/records/1.0/analyze/?dataset=doc-geonames-cities-5000&x=country_code&y.my_count.func=COUNT&geofilter.polygon=(50.0,0.0),(50.0,10.0),(40.0,10.0),(40.0,0.0)
[
{
"x": "AD",
"my_count": 7
},
{
"x": "AT",
"my_count": 16
},
{
"x": "BE",
"my_count": 13
},
{
"x": "CH",
"my_count": 342
},
{
"x": "DE",
"my_count": 677
},
{
"x": "ES",
"my_count": 261
},
{
"x": "FR",
"my_count": 1468
},
{
"x": "IT",
"my_count": 512
},
{
"x": "LI",
"my_count": 11
},
{
"x": "LU",
"my_count": 17
},
{
"x": "MC",
"my_count": 3
}
]
| Parameter | Description |
|---|---|
dataset |
Identifier of the dataset. This parameter is mandatory |
q |
Full-text query performed on the result set |
geofilter.distance |
Limit the result set to a geographical area defined by a circle center (WGS84) and radius (in meters): latitude, longitude, distance |
geofilter.polygon |
Limit the result set to a geographical area defined by a polygon (points expressed in WGS84): ((lat1, lon1), (lat2, lon2), (lat3, lon3)) |
refine.<FACET> |
Limit the result set to records where FACET has the specified value. It can be used several times for the same facet or for different facets |
exclude.<FACET> |
Exclude records where FACET has the specified value from the result set. It can be used several times for the same facet or for different facets |
pretty_print |
If set to true (default is false), pretty prints JSON and JSONP output |
format |
Format of the response output. Can be json (default), jsonp, csv |
csv_separator |
If the format is csv, defines the delimiter used. Can be ; (default), ,, |, or any ASCII character. Special characters may require URL encoding. |
callback |
JSONP callback (only in JSONP requests) |
Aggregation parameters
Return the population size of the biggest city for each country code:
https://documentation-resources.huwise.com/api/records/1.0/analyze/?dataset=doc-geonames-cities-5000&x=country_code&y.max_population.func=MAX&y.max_population.expr=population
[
{
"x": "AD",
"max_population": 20430
},
{
"x": "AE",
"max_population": 2956587
},
/* ... */
{
"x": "ZM",
"max_population": 1267440
},
{
"x": "ZW",
"max_population": 1542813
}
]
| Parameter | Description |
|---|---|
x |
Field on which the data aggregation will be based. This parameter is mandatory. It allows for analyzing a subset of data according to the different values of the fields. The behavior may vary according to the field type. For Date and DateTime fields, the slices are built from the dates using the level of aggregation defined through the precision and periodic parameters. For other field types, the actual field values are used as x values |
y.<SERIE>.func |
The definition of the analysis aggregation function. Multiple series can be computed at once. Simply name this parameter with an arbitrary series name that you may reuse for specifying the associated aggregated expression. The list of available aggregation functions is: COUNT , AVG , SUM , MIN , MAX , STDDEV , SUMSQUARES . These functions return the result of their execution on the expression provided in y.COUNT function) for each value of x |
y.<SERIE>.expr |
Defines the value to be aggregated. This parameter is mandatory for every aggregation function but the COUNT function. The |
y.<SERIE>.cumulative |
This parameter accepts values true and false (default). If the parameter is set to true, the results of a series are recursively summed up (serie(x) = serie(x) + serie(x-1) ) |
maxpoints |
Limits the maximum number of results returned in the serie. By default, there is no limit. |
periodic |
Used only in cases in which x is of type Date or DateTime. It defines the level at which aggregation is done. Possible values are year (default), month , week , weekday , day , hour , minute . This parameter will allow you, for instance, to compute aggregations on months across all years. For instance, with a value set to weekday , the output will be: [{"x": {"weekday":0},"series1": 12}, {"x": {"weekday":1},"series1": 30}] . When weekday is used, the generated value range from 0 to 6 where 0 corresponds to Monday and 6 to Sunday |
precision |
Used only in cases in which X is of type Date or DateTime. It defines the precision of the aggregation. Possible values are year , month , week , day (default), hour , minute . If weekday is provided as a periodic parameter, the precision parameter is ignored. This parameter shall respect the precision annotation of the field. If the field is annotated with a precision set to day , the series precision can at maximum be set to day. |
sort |
Sorts the aggregation values according to the specified series or to the x parameter. By default, the values are sorted in descending order, according to the x parameter. A minus sign ('-') can be prepended to the argument to make an ascending sort |
Expression language
Return the average value of twice the square root of the population for each country code (for the sake of example):
https://documentation-resources.huwise.com/api/records/1.0/analyze/?dataset=doc-geonames-cities-5000&x=country_code&y.series1.func=AVG&y.series1.expr=sqrt(population)*2
[
{
"x": "AD",
"series1": 189.14616030045894
},
{
"x": "AE",
"series1": 849.7322922436006
},
/* ... */
{
"x": "ZM",
"series1": 389.98380339301144
},
{
"x": "ZW",
"series1": 438.7610954217565
}
]
An arbitrary expression can be used as the value of the definition of an aggregated.
- Classical numerical operators are available:
+,-,*,/ - Parenthesis can be used to group sub expressions together
- The following functions are also available:
time,sin,cos,tan,asin,acos,atan,toRadians,toDegrees,exp,log,log10,sqrt,cbrt,IEEEremainder,ceil,floor,rint,atan2,pow,round,random,abs,max,min,ulp,signum,sinh,cosh,tanh,hypot
Records Download API
GET /api/records/1.0/download HTTP/1.1
This API provides an efficient way to download a large set of records out of a dataset. The HTTP answer is streamed, which makes it possible to optimize the memory consumption client side.
Parameters
| Parameter | Description |
|---|---|
dataset |
Identifier of the dataset. This parameter is mandatory |
q |
Full-text query performed on the result set |
geofilter.distance |
Limit the result set to a geographical area defined by a circle center (WGS84) and radius (in meters): latitude, longitude, distance |
geofilter.polygon |
Limit the result set to a geographical area defined by a polygon (points expressed in WGS84): ((lat1, lon1), (lat2, lon2), (lat3, lon3)) |
facet |
Activate faceting on the specified field. This parameter can be used multiple times to simultaneously activate several facets. By default, faceting is disabled. Example: facet=city |
refine.<FACET> |
Limit the result set to records where FACET has the specified value. It can be used several times for the same facet or for different facets |
exclude.<FACET> |
Exclude records where FACET has the specified value from the result set. It can be used several times for the same facet or for different facets |
fields |
Restricts field to retrieve. This parameter accepts multiple field names separated by commas. Example: fields=field1,field2,field3 |
pretty_print |
If set to true (default is false), pretty prints JSON and JSONP output |
format |
Format of the response output. Can be csv (default), json, jsonp, geojson, geojsonp |
csv_separator |
If the format is csv, defines the delimiter used. Can be ; (default), ,, |, or any ASCII character. Special characters may require URL encoding. |
callback |
JSONP or GEOJSONP callback |
Records Geo Clustering API
GET /api/records/1.0/geocluster HTTP/1.1
This API provides powerful geo clustering features over a set of selected records.
The return format can easily be used to build comprehensive data visualizations on a map, using a very large number of records.
This API takes as an input:
- the cluster precision
- a polygon representing the current view on a map
It returns a list of clusters with the number of points contained in each cluster and the polygon of the cluster envelope, along with computed aggregations when required.
The clustering results are returned in JSON.
Filtering parameters
| Parameter | Description |
|---|---|
dataset |
Identifier of the dataset. This parameter is mandatory |
q |
Full-text query performed on the result set |
geofilter.distance |
Limit the result set to a geographical area defined by a circle center (WGS84) and radius (in meters): latitude, longitude, distance |
geofilter.polygon |
Limit the result set to a geographical area defined by a polygon (points expressed in WGS84): ((lat1, lon1), (lat2, lon2), (lat3, lon3)) |
refine.<FACET> |
Limit the result set to records where FACET has the specified value. It can be used several times for the same facet or for different facets |
exclude.<FACET> |
Exclude records where FACET has the specified value from the result set. It can be used several times for the same facet or for different facets |
callback |
JSONP or GEOJSONP callback |
Clustering parameters
Return clusters and shapes with low precision and the average population in each cluster
https://documentation-resources.huwise.com/api/records/1.0/geocluster/?dataset=doc-geonames-cities-5000&shapeprecision=1&clusterprecision=3&clusterdistance=50&y.avg_population.func=AVG&y.avg_population.expr=population
{
"clusters": [
/* ... */
{
"cluster_center": [
64.73423996474594,
177.51029999926686
],
"count": 1,
"series": {
"avg_population": 10332
},
"cluster": {
"type": "Point",
"coordinates": [
177.51029999926686,
64.73423996474594
]
}
},
{
"cluster_center": [
54.03621598239988,
158.9805759564042
],
"count": 5,
"series": {
"avg_population": 54285.8
},
"cluster": {
"type": "Polygon",
"coordinates": [
[
[
158.40468998998404,
52.93109998572618
],
[
158.38134999386966,
53.18908997811377
],
[
158.6206699255854,
54.69609996769577
],
[
160.84540992043912,
56.32034998387098
],
[
158.65075995214283,
53.0444399965927
],
[
158.40468998998404,
52.93109998572618
]
]
]
}
},
/* ... */
],
"count": {
"max": 5473,
"min": 1
},
"series": {
"avg_population": {
"max": 645386.6153846154,
"min": 2
}
},
"clusterprecision": 3
}
| Parameter | Description |
|---|---|
clusterprecision |
The desired precision level, depending on the current map zoom level (for example, the Leaflet zoom level). This parameter is mandatory |
shapeprecision |
The precision of the returned cluster envelope. The sum of clusterprecision and shapeprecision must not exceed 29 |
clusterdistance |
The distance from the cluster center (the radius). This parameter is mandatory |
clustermode |
The desired clustering mode. Supported values are polygon (default) and heatmap |
y.<SERIE>.func, y.<SERIE>.expr |
This API also accepts a series definition as described in the record analysis API. If a serie is defined, the aggregation will be performed using the values of the series. |